注册登录后全站资源免费查看下载
您需要 登录 才可以下载或查看,没有账号?立即注册
×
转载自吾爱破/解论坛
某摄像头协议分析环境- 主机:win10
- 手机:Pixel 4 ,Android 10
- APP版本:V4.70.0
工具IDA、JADX、Frida、Charles、WireShark、x64dbg 逆向思路总结:抓包 -> 分析数据包特征 -> 确定UDP/TCP -> HOOK 发包函数 -> 分析代码 -> 验证 流量抓包分析经过抓取APP与摄像头之间通信的流量,发现以下几种固定特征流量。 magic: 3acf872a 经过反复抓包,发现同一个包有以下特征:
> 3a cf 87 2a 00 01 00 00 01 00 00 00 这12个字节固定不变,后面的数据在变。 不同包,同样的magic,对比后发现原先12个字节的中间四字节会变化。 如下: 同一个包的client和server包,对比后发现原先12个字节的中间四字节也会变化,其他部分相似度很高。如下: 
最终发现,整个数据长度为0x11c,中间四字节为0x00000100,那么我们可以得出真实数据为magic往后20字节,其他字节含义未知。
magic: 20cf872a 这个数据包比较简单,整体固定不变,可能保活心跳之类的数据包。
- magic: 10cf872a
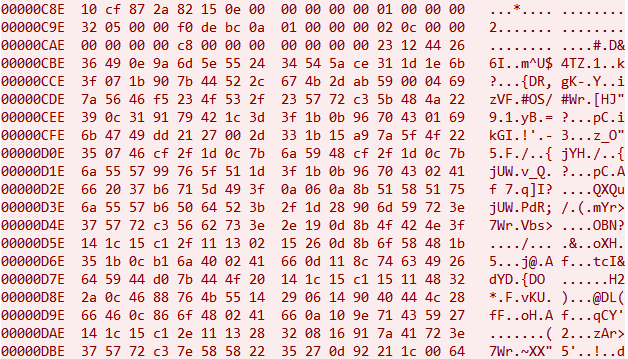
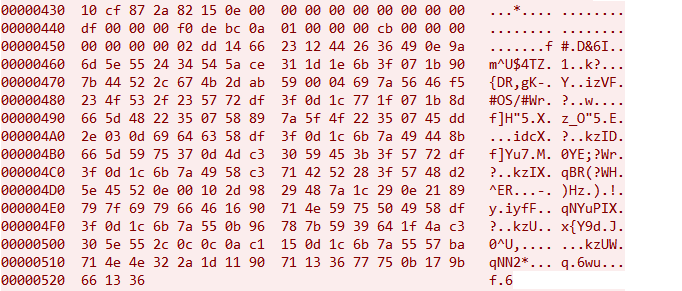
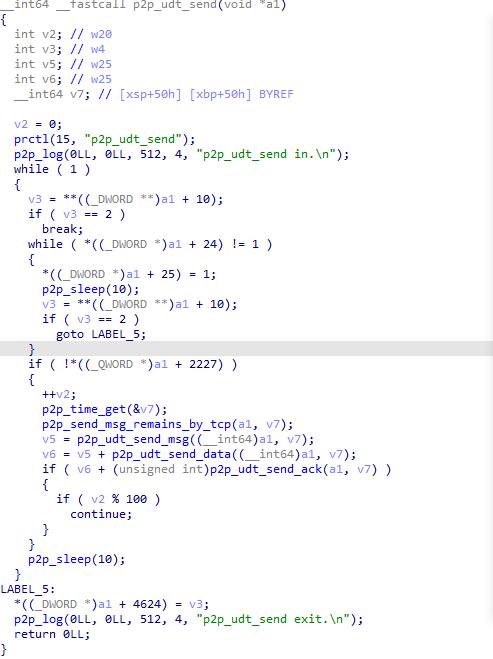
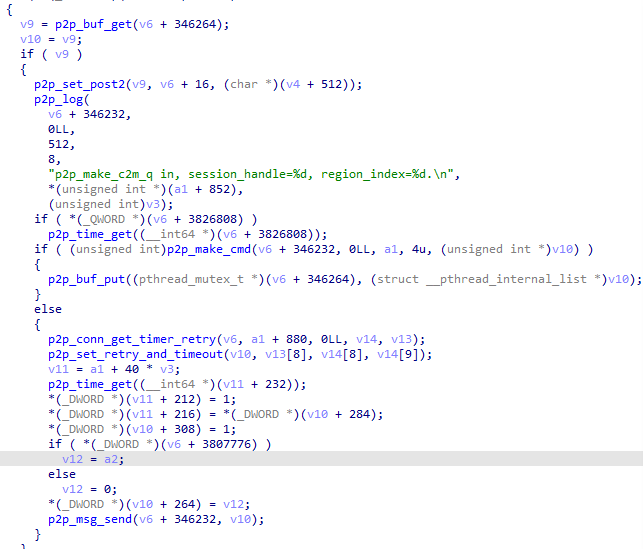
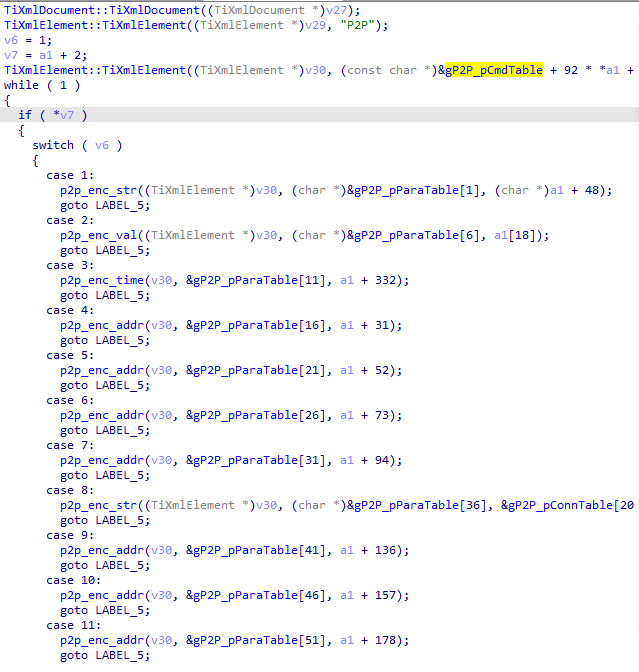
通过对比,也可以发现前16个字节后的四字节为数据长度,而这个包数据似乎里面还嵌套这另外的数据结构。 三种特征数据都是通过UDP传输,接下来的思路就是Hook libc.so 的sendto函数,打印调用堆栈。 查壳、脱壳未查到,那就先将APK拖进JADX里进行分析。 Frida Hook撸起袖子就准备直接开干,Frida Server已启动,直接运行,HOOK libc.so的sendto函数,并打印堆栈。 加解密流程分析经过回溯信息来看,相关函数都在libp2pc.so里面。这时候可以确定的是magic: 20cf872a为ACK,使用IDA打开该so,打开p2p_send_msg_by_udp函数,发现里面并没有加密相关函数,最终追溯追到下面这个函数就戛然而止了!!! 进入p2p_udt_send_msg函数中,也没有发现相关加解密函数,全部都在取数据,然后发送。 分析发现,所有操作基于多线程。到这断了思路。 代码翻来翻去,注意到了这个p2p_log函数,既然静态分析不行,那就看看log日志,了解整个流程,HOOK p2p_log函数后打印已知字符串,就可以得到一大堆log。 经过观察,字符串最前的应该是函数名,那么去p2p_conn_get_timer_retry函数看看。 里面也没啥重要函数,在看看p2p_make_c2m_q函数。 到这里,基本上有点头绪了,点进p2p_make_cmd函数看看。 最终找到了主体函数p2p_enc_cmd,在这个函数里面,进行了参数组装。 gP2P_pCmdTable里面是字符串表,如下: 里面字符大概有C2D_S、C2M_Q之类的 gP2P_pParaTable也是字符串表,如下: 里面字符大概有uid、sid之类的 数据结构上是一个xml结构,大概是下面这种: <P2P>\n<C2M_Q>....</C2M_Q>\n</P2P>
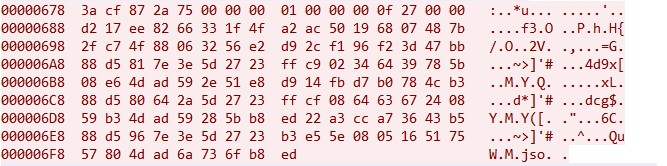
通过交叉引用,发现了加解密的地方。 magic: 3acf872a数据通过HOOK p2p_encrypt_and_decrypt和p2p_calc_crc函数后,发现这里就是magic: 3acf872a数据组装和加密的地方,至此该数据包结构解清晰了。 <br/> magic data size unknown transmission id checksum payload
3a cf 87 2a44 01 00 0000 00 00 00a4 0c 3d 0095 49 09 56d3.....- 4 Bytes magic: 3a cf 87 2a
- 4 Bytes data size: 加解密数据长度
- 4 Bytes unknown: 固定字节,含义未知
- 4 Bytes Transmission ID: 加解密所需的key
- 4 Bytes Checksum: 加密后数据的CRC32校验值
- n Bytes Payload: 加解密数据
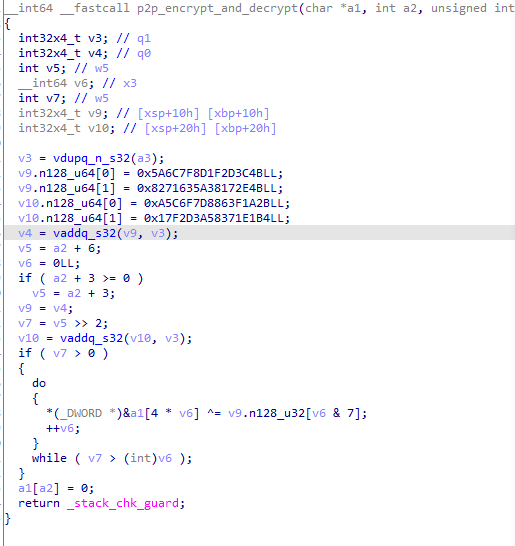
数据包结构清晰了,现在就要还原加解密算法了,在IDA里查看p2p_encrypt_and_decrypt伪码。 看起来就是简单的xor操作,但这里面有些函数比较陌生,比如 复制代码 隐藏代码
v9.n128_u64[0] = 0x5A6C7F8D1F2D3C4BLL;v9.n128_u64[1] = 0x8271635A38172E4BLL;v10.n128_u64[0] = 0xA5C6F7D8863F1A2BLL;v10.n128_u64[1] = 0x17F2D3A58371E1B4LL;v3 = vdupq_n_s32(a3);v9.n128_u64[0] = 0x5A6C7F8D1F2D3C4BLL;v9.n128_u64[1] = 0x8271635A38172E4BLL;v10.n128_u64[0] = 0xA5C6F7D8863F1A2BLL;v10.n128_u64[1] = 0x17F2D3A58371E1B4LL;v4 = vaddq_s32(v9, v3);于是去问了一下Google,这种是ARM NENO指令集,一种基于SIMD思想的ARM技术,NEON结合了64-bit和128-bit的SIMD指令集,提供128-bit宽的向量运算(vector operations)。有兴趣的看下这篇文章NEON简介及基本架构,这里就不多赘述了。 那么接下来,就该祭出大杀器-ex咖喱棒了 以下是chatgpt的回答: - vdupq_n_s32(a3):将 a3 的值复制到一个 128 位向量中的每个元素,生成一个包含相同值的向量 v3。
- v9 和 v10 是两个 128 位向量变量,初始化为指定的常数值,通过 .n128_u64[0] 和 .n128_u64[1] 分别访问向量的第一个和第二个 64 位整数成员。
- vaddq_s32(v9, v3):将向量 v9 和向量 v3 中的对应元素相加,生成一个新的向量 v4。
- a2 + 6 和 a2 + 3 是用于确定循环次数的值。根据这些值,计算出需要处理的向量元素个数 v7。
- 进入循环,使用 NEON 指令进行加密和解密操作。(_DWORD )&a1[4 * v6] 是对字符数组 a1 的访问,v9.n128_u32[v6 & 7] 是对向量 v9 的访问。^= 操作符表示按位异或运算,将结果存储回字符数组 a1 中。
- 循环结束后,将字符数组 a1 的第 a2 个元素设置为 0。
通过HOOK p2p_encrypt_and_decrypt函数可知,a1为加解密原数据,a2为数据长度,a3为加解密所需的key。 我们逐句翻译IDA伪码,使用Python复现。 复制代码 隐藏代码
v3 = vdupq_n_s32(a3);将a3转换成4个short32的值并赋值给128 位向量变量V3。我们使用numpy库去实现。 复制代码 隐藏代码
v3 = np.full(4, a3, dtype=np.int32) 复制代码 隐藏代码
v9.n128_u64[0] = 0x5A6C7F8D1F2D3C4BLL;v9.n128_u64[1] = 0x8271635A38172E4BLL;v10.n128_u64[0] = 0xA5C6F7D8863F1A2BLL;v10.n128_u64[1] = 0x17F2D3A58371E1B4LL;.n128_u64[0]代表128位的前64位,.n128_u64[1]代表128位的后64位,而v9为4个int32的数组。根据高低位再把128位分为4个32位整数即可。小端计算。 复制代码 隐藏代码
v9 = [0x1F2D3C4B, 0x5A6C7F8D, 0x38172E4B, 0x8271635A]v10同理。 复制代码 隐藏代码
v10 = [0x863F1A2B, 0xA5C6F7D8, 0x8371E1B4, 0x17F2D3A5]vaddq_s32(v9, v3),v9 和v3 中的对应元素相加,short32类型保存。Python中使用lambda表达式实现相加,并转化为list数组。 复制代码 隐藏代码
v4 = list(map(lambda x, y: x + y, v3, v9))v10同理。 复制代码 隐藏代码
v10 = list(map(lambda x, y: x + y, v10, v3))其他就是正常翻译就行了。完整代码如下: 复制代码 隐藏代码
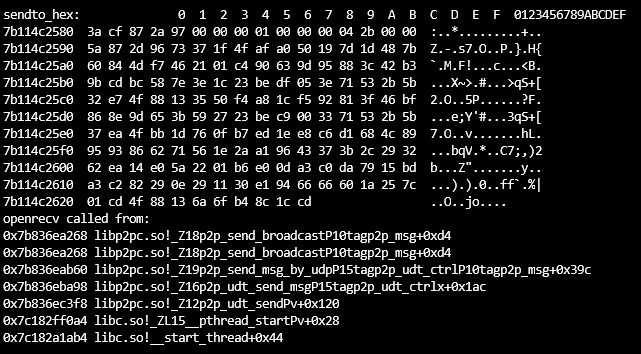
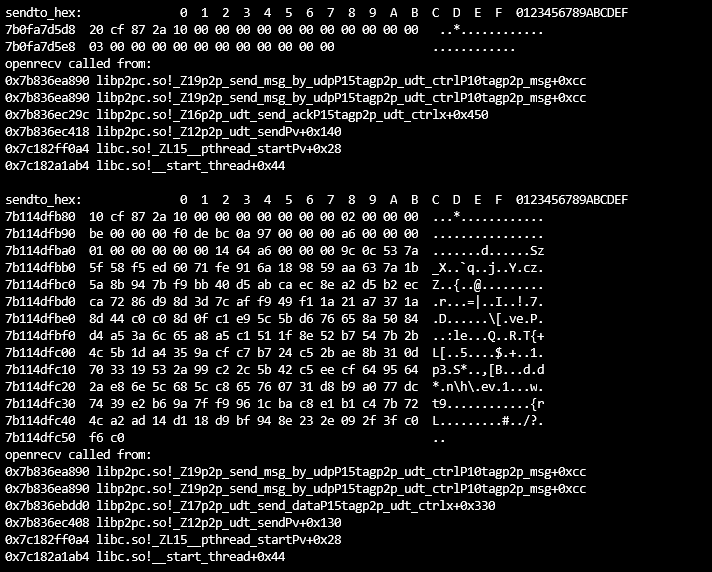
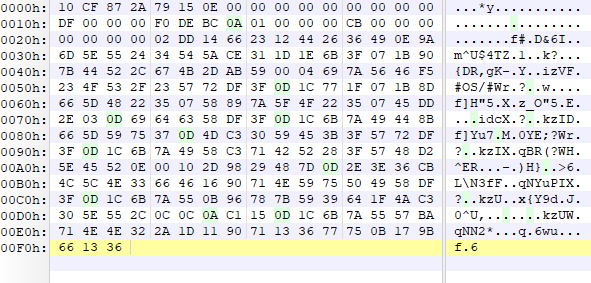
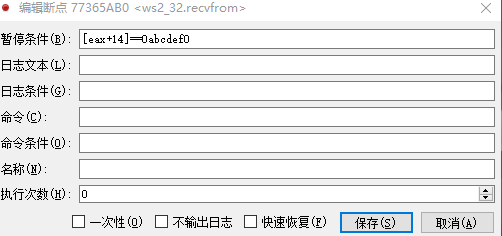
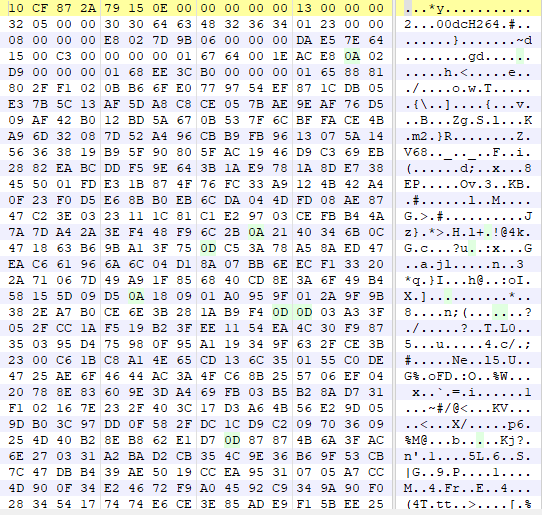
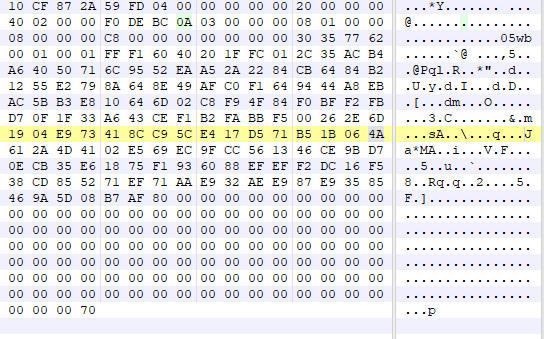
def p2p_decrypt(a1, a2, a3): # 计算填充的字节数 padding_bytes = (4 - (a2 % 4)) % 4 # 添加填充字节 a1 += b'\x00' * padding_bytes # 将a1字节数组转换为四字节整数的列表 enc_data = list(struct.unpack(f"<{len(a1) // 4}I", a1)) # 将a3字节数组转换为四字节整数的列表 v3 = np.full(4, a3, dtype=np.int32) print("解密key四字节整数的列表: ", v3) # 小端计算 # v9 = [0x8271635A, 0x38172E4B, 0x5A6C7F8D, 0x1F2D3C4B] v9 = [0x1F2D3C4B, 0x5A6C7F8D, 0x38172E4B, 0x8271635A] # v10 = [0x17F2D3A5, 0x8371E1B4, 0xA5C6F7D8, 0x863F1A2B] v10 = [0x863F1A2B, 0xA5C6F7D8, 0x8371E1B4, 0x17F2D3A5] # 将v3和v9整数列表里的整数一一对应相加 v4 = list(map(lambda x, y: x + y, v3, v9)) # print(v4) v7 = len(a1) >> 2 print("解密数据循环次数: ", v7) # 将v3和v10整数列表里的整数一一对应相加 v10 = list(map(lambda x, y: x + y, v10, v3)) # 将v4和v10整数列表里的整数一一对应相加 v9 = v4 + v10 if v7 > 0: for v6 in range(v7): # print(hex(a1[v6]), hex(v9[v6 & 7])) # 将加密数据整数列表里的整数与v9整数列表里的整数进行异或 enc_data[v6] ^= v9[v6 & 7] # a1[a2] = 0 # 转换为小端存储的十六进制字符串 hex_string = ''.join([struct.pack('<I', num).hex() for num in enc_data]) hex_string_len = len(bytes.fromhex(hex_string)) if padding_bytes > 0: hex_string = bytes.fromhex(hex_string)[:hex_string_len - padding_bytes] print("解密数据异或后16进制数据: ", hex_string) return hex_string else: hex_string = bytes.fromhex(hex_string) print("解密数据异或后16进制数据: ", hex_string) return hex_string至此,magic: 3acf872a数据的解密接完成了。 接下来我们看另外一个数据,magic: 10cf872a。 上面提到该数据包含两种数据结构,经过观察研究发现,一种是加密数据,一种是明文音视/频数据。 magic: f0debc0a数据加密数据 具体形式如下: 可以看出大体结构为10 CF 87 2A ......F0 DE BC 0A。经过和其他包对比发现DF 00 00 00 和CB 00 00 00为数据长度,其他字段未知。 Frida大法暂时失效了,无法应对多线程,打印堆栈只有一些不痛不痒的东西。 索性开辟新天地,盯上了它的PC版本。 打开软件,使用x64dbg附加,由于我们只关注同时包含10 CF 87 2A和F0 DE BC 0A的数据,因此可以在recvfrom函数上下条件断点,条件即buf = F0 DE BC 0A,设置如下: 最终堆栈情况如下: 使用IDA加载该dll,并跳转到0F69872D这个地址。为了方便x64dbg与IDA之间跳转,我们先将IDA的基址改为x64dbg里面的。反编译0F69872D,得到伪码如下: 经过分析发现,会进入sub_F697CC0这个函数,在跟进去看看。 反编译该函数代码后往下翻一翻就看到了比较关键的代码,如下: <br/> 根据sub_F772AF0函数打印的结果和原报文数据对比可知magic: 10cf872a的数据结构大体如下: <br/> magic connection id unknown packet id packet size payload
10 cf 87 2a79 15 00 0000 00 00 0000 00 00 0101 dc 00 0014.....- 4 Bytes magic: 10 cf 87 2a
- 4 Bytes Connection ID: UDP 连接ID
- 4 Bytes unknown: 固定为00000000
- 4 Bytes Packet ID: 包序
- 4 Bytes Payload Size: 数据大小
- n Bytes Payload: 加密数据
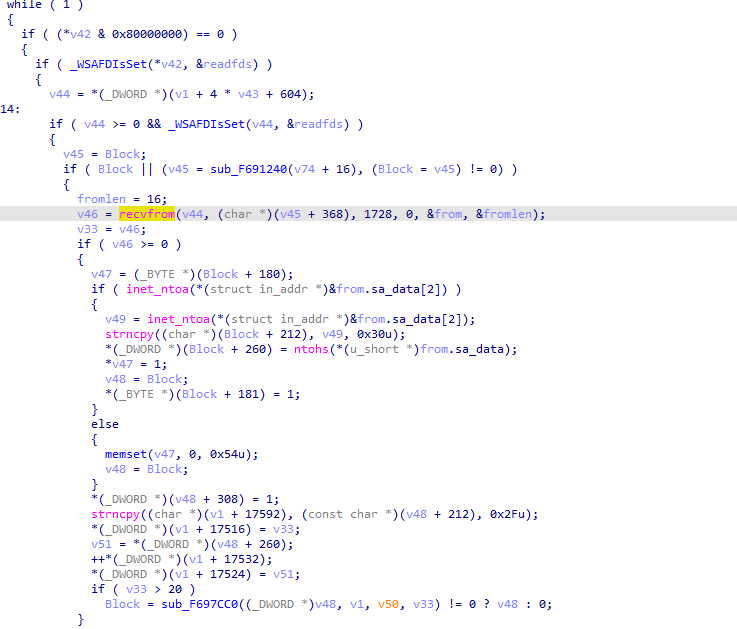
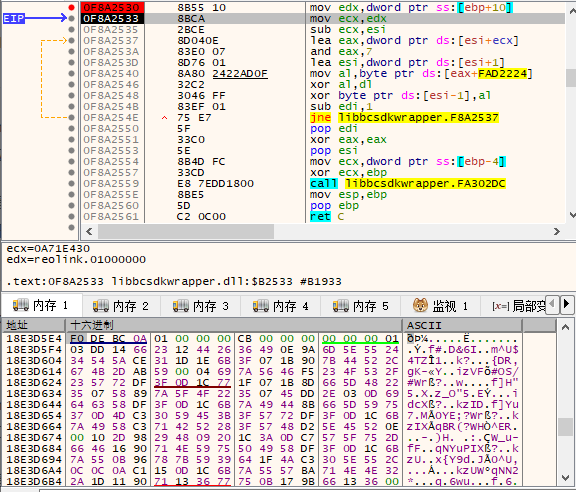
到这本想投机取巧一下,大胆猜测是同一种加解密方法,于是就用magic: 3acf872a数据的解密方法,拿Connection ID当作key尝试解密了一下,结果失败了。 到这只能继续分析找出该数据块的解密方法。 本想跟上一个数据一样通过字符串去定位,最终失败。只能通过调试去慢慢寻找,多线程操作,跳来跳去,真的掉头发哦。 x64dbg这块玩的并不是很熟,所以并不知道如何快速在调用堆栈中找到相关线程,有大佬知道的话,烦请指导一二,不甚感激!!!! 查了查Google也没找到技巧,那就只能铁杵磨成针,一个一个的拿着地址去IDA里面看。最/后发现了一个线程里的函数代码非常的像。
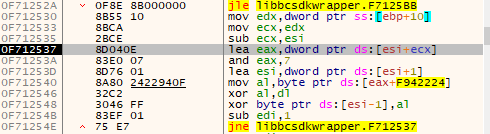 反编译伪码如下: 我们在函数头和循环异或这里打个断点看一下。运行程序,断在函数头。 可以看到eax里的值即为去掉第一个数据结构(10 cf 87 2a)后的数据。再次F9断下刚刚循环异或的地方。 复制代码 隐藏代码
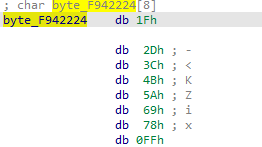
mov edx, [ebp+10h]mov ecx, edxsub ecx, esilea eax, [esi+ecx]and eax, 7计算byte_F942224的index。 复制代码 隐藏代码
lea esi, [esi+1]mov al, byte_F942224[eax]xor al, dlxor [esi-1], alsub edi, 1esi地址存储的为加密数据,每次取一个字节与byte_F942224数组里的一字节异或。 将其翻译为Python代码如下: 复制代码 隐藏代码
def xml_decrypt(ba, offset): key = bytearray([0x1f, 0x2d, 0x3c, 0x4b, 0x5a, 0x69, 0x78, 0xff]) e = bytearray(len(ba)) for i in range(len(ba)): xor_result = operator.xor(offset & 0xFF, operator.xor(ba, key[(i + offset) % 8])) e = xor_result print(e.decode('utf-8')) return emagic:f0debc0a数据的加密方式就分析完了。通过上述代码分析,可得该数据结构大体为以下几种: magic message id message length encryption offset encrypt message class payload
f0 de bc 0a01 00 00 002c 07 00 0000 00 00 0101 dc14 652d.....- 4 Bytes magic: f0 de bc 0a
- 4 Bytes Message ID: 消息ID
- 4 Bytes Message Length: 消息体长度
- 4 Bytes Encryption Offset: 加密key
- 2 Bytes Encryption flag: 加密标志
- 2 Bytes Message class: 消息类型
- n Bytes Payload: 加密数据
Or Magic Message ID Message Length Encryption Offset Status Code Message Class payload
f0 de bc 0a01 00 00 0028 01 00 0000 00 00 01c8 0014 643b....<br/> - 4 Bytes magic: f0 de bc 0a
- 4 Bytes Message ID: 消息ID
- 4 Bytes Message Length: 消息体长度
- 4 Bytes Encryption Offset: 加密key
- 2 bytes Status Code:消息状态码
- 2 bytes Message class:消息类型
- n bytes Payload:加密数据
音视/频数据音视/频magic如下: - I Frame: 0x30, 0x30, 0x64, 0x63
- P Frame: 0x30, 0x31, 0x64, 0x63
- AAC: 0x30, 0x35, 0x77, 0x62
视/频数据内容如下: 还是经典的10 cf 87 2a结构,去除这个结构后就是视/频数据结构了。结构大体如下: - 4 Bytes I_frame_magic/P_frame_magic:视/频I/P帧magic
- 4 Bytes video_type:视/频类型-H264/H265
- 4 Bytes video_len:视/频数据长度
- 4 Bytes channel:NVR 频道号
- 4 Bytes microseconds:NVR的时间戳精度
- 4 Bytes unknown:固定字节
- 4 Bytes utc_time:UTC时间
- 4 Bytes unknown:固定字节
- n Bytes video_data:视/频数据
音频数据内容如下: 头部数据相同,这里不再赘述,直接看音频数据部分。 <br/> - 4 Bytes audio_magic:音频数据magic
- 2 Bytes audio_len:音频数据长度
- 2 Bytes audio_len:音频数据长度
到这里有关该摄像头的所有流量就分析完成了。 这可是吾爱的精华
|







 名望
名望 星币
星币 星辰
星辰 好评
好评










 发表于 2023-7-27 08:39:26
发表于 2023-7-27 08:39:26










 提升卡
提升卡 变色卡
变色卡